In plain English
Most coding tests ask an AI to write one small function in a blank file: "reverse a string," "check if a number is prime." That tells you almost nothing about whether the model can survive in a real codebase, where the answer is buried across many files and a single wrong edit breaks fifty other things.
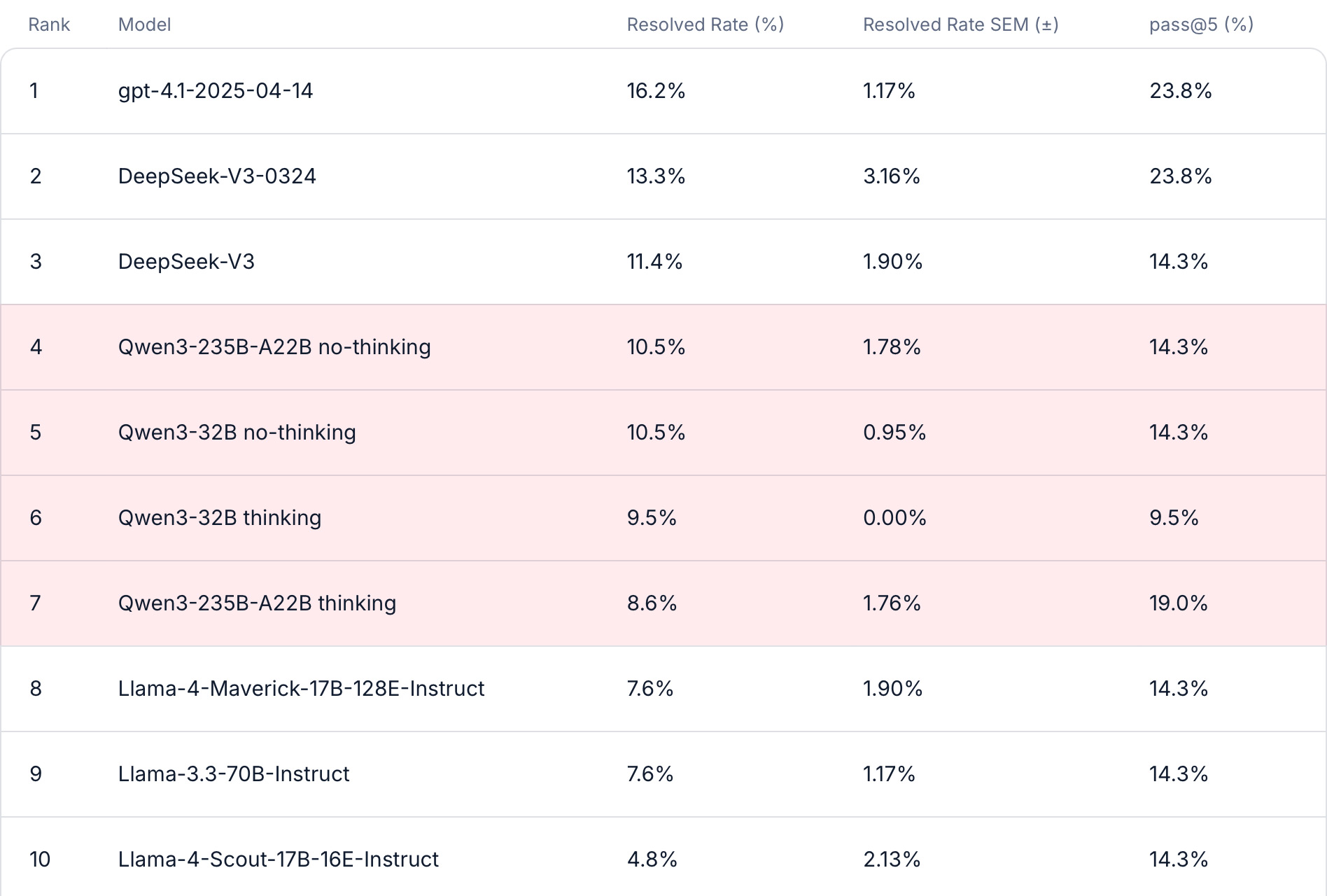
SWE-bench (pronounced "swee-bench," short for software engineering benchmark) tests the harder, real-world skill. It takes thousands of actual bug reports and feature requests from popular open-source Python projects on GitHub, hands the model the same project and the same issue a human developer faced, and asks: can you produce a code change that fixes this?
Here is the clever part: nobody grades the answer by eye. Each issue comes from a real pull request that a human already merged, and that pull request included tests. SWE-bench runs the project's test suite against the model's patch. If the tests that were failing now pass — and nothing else breaks — the model passes. If not, it fails. There is no partial credit and no opinion involved; the repository's own tests are the judge.
Why it matters
For years, coding ability was measured by benchmarks like HumanEval, where a model writes a single self-contained function from a docstring. Models got very good at those, and the scores stopped being useful — they had saturated. A near-perfect score no longer told you which model could actually help on a serious project.
SWE-bench matters because it raised the bar to something closer to a real engineer's day:
- It is grounded in real work, not toy puzzles. The tasks are genuine issues from widely used libraries (think Django, scikit-learn, matplotlib, sympy). The model has to understand existing code it did not write.
- It rewards finding the problem, not just typing code. A task often spans a large repository. Most of the difficulty is locating which file and which lines to change — the same skill that makes human debugging hard.
- The grading is objective and reproducible. Because real tests decide pass or fail, there is no fuzzy human rubric and no chance for a confident-but-wrong answer to sneak through. The same patch gives the same result every time.
- It became the headline number for coding agents. When a lab announces a new model and says it is better at software engineering, SWE-bench (usually the Verified subset) is the score everyone now expects to see.
For a builder choosing a model for a coding tool or an autonomous agent, SWE-bench is one of the few public signals that correlates with real usefulness on a codebase, rather than the ability to ace isolated puzzles. That is exactly why it spread so fast and became a default reference point.
How it works
Each SWE-bench task instance is built from one real merged pull request. The benchmark strips the PR back to its starting point and reconstructs the situation the original developer faced.
A single task gives the model:
- The issue text — the natural-language bug report or feature request, exactly as it was written on GitHub.
- The repository at the right commit — a snapshot of the whole codebase from just before the fix was merged, so the bug is still present.
- Nothing else. The model does not see the human's solution or which tests will be run. It must find and fix the problem on its own.
The model's job is to output a patch: a diff describing which lines in which files to change. SWE-bench applies that patch to the repository, then runs two sets of tests inside an isolated environment (usually a Docker container so every run is clean and identical).
The two test sets are what make the grading both strict and fair:
- FAIL_TO_PASS — the tests that were failing because of the bug and that the human fix made pass. The model's patch must turn these green. This proves the bug is actually fixed.
- PASS_TO_PASS — tests that were already passing before. They must stay green. This proves the patch did not break anything else (no regressions).
A task counts as resolved only if every FAIL_TO_PASS test now passes and every PASS_TO_PASS test still passes. A model's SWE-bench score is simply the percentage of tasks it resolves. There is no credit for a patch that fixes the bug but breaks something else — exactly like real code review.
SWE-bench, Verified, Lite, and friends
"SWE-bench" is now an umbrella name for a family of related sets. Knowing which one a score refers to is essential, because the numbers are not comparable across variants.
| Variant | What it is | Why it exists |
|---|---|---|
| SWE-bench (full) | The complete original set of task instances across many Python repos | The broadest, hardest test of real-world fixes |
| SWE-bench Verified | A human-validated subset where engineers confirmed each task is solvable and fairly specified | Removes broken or impossible tasks so the score reflects real ability |
| SWE-bench Lite | A smaller, cheaper subset of self-contained tasks | Lets teams run quick, low-cost evaluations |
| SWE-bench Multimodal | Tasks that also involve images, such as front-end and visual bugs | Tests fixing issues that include screenshots or rendered output |
Verified is the one you will see most often. The original full set contained some tasks that were essentially unsolvable — the issue description left out a key detail, or the hidden tests checked behavior nobody could have guessed. A team of professional developers reviewed a large sample and kept only the tasks that a reasonable engineer could actually solve from the information given. When a lab reports "X% on SWE-bench," it almost always means SWE-bench Verified, so always check which variant a headline number refers to before comparing two models.
The model is only half the score
A subtle point that trips up newcomers: a SWE-bench result is not produced by a model alone. It is produced by a model plus the scaffolding around it — the loop that lets the model explore the repository, read files, run commands, and try again. This wrapper is often called an agent or a harness.
The same underlying model can score quite differently depending on its scaffolding. A good harness gives the model tools to search the codebase, view file contents, edit lines, run the tests itself, and use the results to fix its own mistakes. A weak harness that just asks for a patch in one shot will score far lower.
This is why SWE-bench is described as an agentic benchmark. It rewards the whole system's ability to investigate and iterate, much like a real developer who reads, tries, runs the test suite, and adjusts. When you read a leaderboard, remember you are seeing model + harness together, not a pure property of the model. Learn more about the broader idea in what is an AI agent.
Limits and fair criticism
SWE-bench is the best public coding benchmark we have, but it is not the last word. Use it with eyes open.
- It is saturating. Top models and harnesses now resolve a large share of SWE-bench Verified. As scores climb toward the ceiling, the remaining gap between models shrinks and the benchmark loses its power to separate them — the same fate that hit older coding tests.
- Contamination risk. The tasks come from public GitHub repos that may already be inside a model's training data. If a model saw the original fix during training, a high score can reflect memorization rather than genuine problem-solving.
- Tests are a proxy, not the truth. Passing the tests means the listed tests pass — not that the fix is complete, secure, or well-designed. A patch can satisfy the tests in a hacky or narrow way that a human reviewer would reject.
- Python-centric and library-flavored. The classic set is Python open-source libraries. It does not directly measure skill in other languages, in large proprietary systems, or on tasks like front-end work or infrastructure.
Going deeper
Once the basics click, a few deeper themes are worth understanding.
Resolved rate vs. cost and steps. A model that resolves a task in three tool calls and a model that needs fifty both get the same point on the leaderboard, but they are wildly different to run in production. Mature evaluations look beyond the headline percentage at how many steps, how much wall-clock time, and how many tokens a successful run took. The cheapest path to a green test matters in real use.
The harness is a research area of its own. Because model + scaffolding together produce the score, a lot of progress comes from better agent loops, not just better models — smarter file search, better ways to localize the bug, and self-checking against the tests before submitting. Two teams running the identical model can land on very different scores.
Why benchmarks keep needing successors. SWE-bench exists because HumanEval saturated; in time, harder successors and "live" variants drawn from very recent issues (to dodge contamination) follow SWE-bench. This is the normal life cycle of a benchmark: it is useful precisely while it is hard, and the field keeps building new ones as the old ones are beaten. To see this pattern across the whole landscape, read what are LLM benchmarks and the dedicated coding benchmarks: HumanEval and SWE-bench explainer.
Read the methodology, not just the number. When a result claims a SWE-bench score, the honest questions are: which variant (Verified, full, Lite)? what harness and how many attempts? was the test set possibly in training data? The benchmark is only as trustworthy as the setup that produced the number, which is the durable lesson behind how to read a benchmark score.
FAQ
What is SWE-bench in simple terms?
SWE-bench is a benchmark that tests whether an AI can fix real software bugs. It gives the model an actual GitHub issue plus the project's code, asks for a patch, and then runs the project's own tests. The model passes only if its change makes the failing tests pass without breaking the ones that already worked.
What is SWE-bench Verified and how is it different?
SWE-bench Verified is a human-checked subset of the original benchmark. A team of engineers reviewed tasks and kept only those that are clearly solvable and fairly specified, removing broken or impossible ones. It is the version most labs report, so Verified scores are higher than full-set scores and the two are not directly comparable.
How is a SWE-bench answer graded?
Automatically, by running tests — no human opinion is involved. The model's patch must turn the bug's previously failing tests green (FAIL_TO_PASS) while keeping all previously passing tests green (PASS_TO_PASS). A task is 'resolved' only if both conditions hold, and the score is the percentage of tasks resolved.
Does a high SWE-bench score mean a model is a great coder?
It is a strong signal but not the whole story. The score reflects the model plus its agent scaffolding working together, the tasks are mostly Python open-source libraries, and passing tests does not guarantee clean or secure code. Treat it as one useful data point alongside your own evaluation on tasks like yours.
Why is SWE-bench called an agentic benchmark?
Because strong results come from letting the model act like a developer in a loop: search the repository, open files, edit code, run the tests, and fix its mistakes based on the results. That investigate-and-iterate behavior is what we call an agent, so SWE-bench measures the whole system, not a single one-shot answer.
Is SWE-bench still a good benchmark if scores are getting high?
It is saturating, which means the best systems already resolve a large share of tasks and the gap between top models is shrinking. It remains useful as one signal, but the field is moving toward harder and contamination-resistant successors, just as SWE-bench itself replaced older, saturated coding tests.