In plain English
When context windows ballooned past 100K tokens, then 1M, a reasonable question emerged: if you can just paste your entire knowledge base into the prompt, why bother building a retrieval pipeline? It is a fair challenge. The answer is that "can" and "should" are different questions — and the gap between them is where real engineering decisions live.
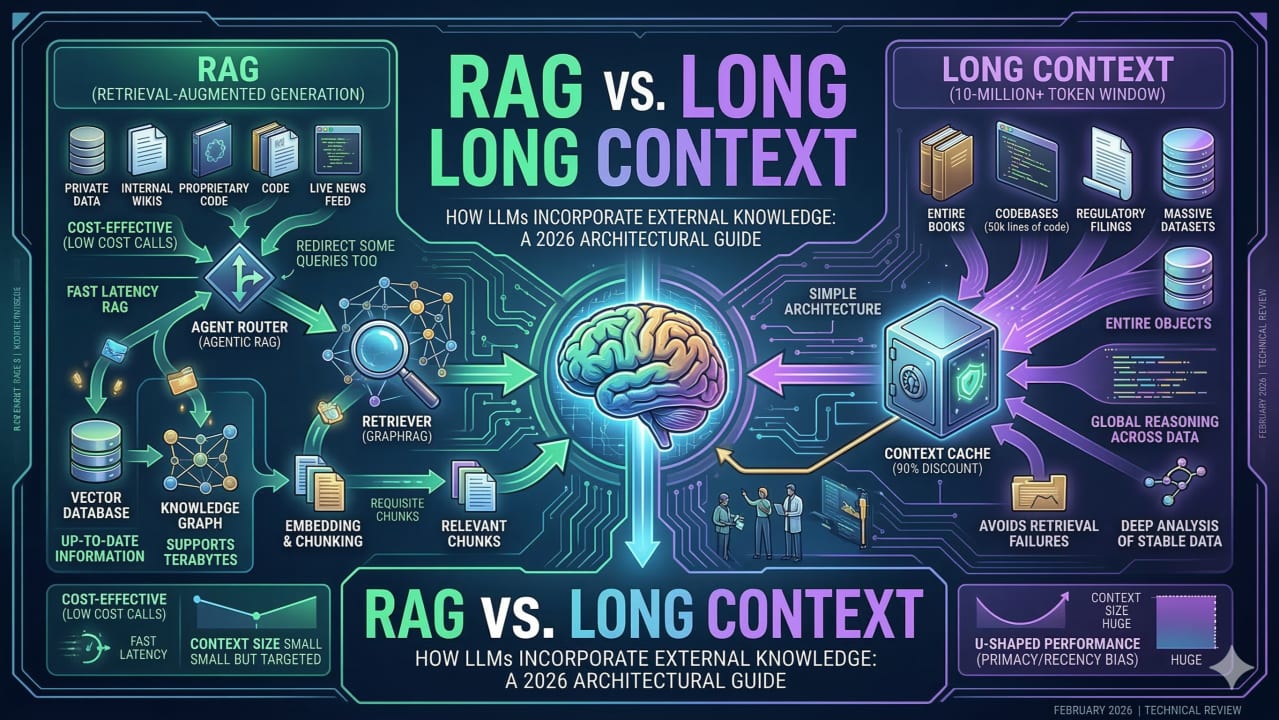
Think of it this way. RAG is like a librarian who sprints to the shelf, grabs the three most relevant books, and hands them to the model. Long context is like handing the model the entire library at once and asking it to find what it needs. Both approaches can produce the right answer. The question is what you pay — in money, in seconds, and in accuracy — for each one.
As of 2025-2026, the leading models support genuinely large windows: frontier models like Gemini, Claude, and the GPT-5 series now reach into the million-token range, with Claude Sonnet 4.6 supporting up to 1M tokens. These are real, usable windows — not marketing numbers. But none of that eliminates the cost, latency, and scale constraints that make RAG the right architecture for most production systems.
Why it matters
Choosing the wrong approach has hard downstream consequences. Pick long context when your data is large and dynamic, and you will burn through API budget in hours and see latencies that make conversational applications unusable. Pick RAG when your corpus is a single static document and every query needs to reason across all of it, and you will fight retrieval precision problems that a simple prompt would never have had.
The debate also matters because both sides have real wins. Long context genuinely outperforms RAG on tasks that require holistic reasoning — summarizing a full legal contract, comparing figures scattered across a 50-page report, or reasoning about the relationship between two sections that a retriever might split across separate chunks. RAG genuinely outperforms long context on large, dynamic corpora where only a small fraction of knowledge is relevant to any single query, and where millisecond response times and tight cost budgets are non-negotiable.
In practice, teams that picked a side in 2023 and never revisited it are leaving value on the table. The right architecture in 2025 is usually a routing strategy: send tasks to long context or retrieval depending on what the query actually needs.
How each approach works
The RAG path
RAG splits the problem into two phases. At index time, documents are chunked, embedded into vectors, and stored in a vector database. At query time, the query is embedded, nearest-neighbor search finds the most semantically relevant chunks, and only those chunks are sent to the model as context. The model sees a short, focused prompt and returns an answer grounded in real documents.
The long-context path
Long context skips the retrieval infrastructure entirely. The full corpus — or a large slice of it — is loaded into the prompt on every request. The model attends over the entire input and synthesizes an answer. There is no vector database, no embedding model, no retrieval precision to tune. The model can reason freely across all the loaded content.
The structural difference
RAG separates selection from reasoning — a retriever picks what the model reads; then the model reasons over that selection. Long context collapses them — the model does both in a single forward pass. That collapse is elegant when the corpus is small and queries need full-document reasoning. It becomes a liability when the corpus is large, because the cost scales linearly with every token loaded on every request.
Cost, latency, and accuracy compared
Cost
Token cost is the sharpest wedge between the two approaches. A RAG query sends a short prompt to the model — typically 1K-5K tokens of retrieved context plus the question. A long-context query sends the full corpus: 100K-1M tokens. At production query volumes, that difference is multiplicative. Benchmarks from 2024 put the long-context cost at roughly 125x more per query than an equivalent RAG pipeline on the same underlying model; at tens of thousands of queries per day the gap reaches 1,250x.
Context caching significantly narrows this gap for static corpora. Gemini discounts cached input tokens steeply (you pay a small fraction of the standard rate for tokens already cached). Claude offers a similar read discount on cached prompt prefixes. If the same large context is reused across many requests within a caching window, the effective per-query cost drops substantially. But caching has limits: Claude's cache evicts after 5 minutes of idle time, making it unreliable for sporadic traffic patterns. Gemini's explicit caching requires a minimum of 2,048 tokens and the cache must be refreshed periodically.
Latency
Token count drives time-to-first-token. Real-world measurements across similar workloads put long-context queries at 10-25x higher latency than RAG. A RAG pipeline typically delivers end-to-end responses in 1-2 seconds; an equivalent long-context configuration on the same model can take 30-60 seconds. For any conversational or interactive application, 45-second p50 latency is a non-starter regardless of answer quality.
Accuracy
Accuracy is more nuanced than cost and latency. Long context wins on holistic tasks — queries that require reasoning across the full corpus, comparing sections, or synthesizing a document as a whole. For simple factual lookups, one study found long context was 34% more accurate on single-fact retrieval because there was no retrieval precision failure mode. For multi-hop synthesis across documents from different time periods, RAG was 67% more accurate, because the retrieved chunks were precisely targeted and the model wasn't distracted by irrelevant content.
The older "Lost in the Middle" problem — where models degraded 30-50% on facts buried mid-context — has improved dramatically. Current frontier models from Google and OpenAI both advertise near-perfect needle-in-haystack recall. But multi-fact retrieval across a very long context remains weaker than clean retrieval; RAG average recall on realistic tasks still hovers around 60%, which means 40% of relevant facts are silently missed. Neither architecture is perfect.
| Dimension | RAG | Long context |
|---|---|---|
| Cost per query (large corpus) | Low — only retrieved chunks billed | High — full corpus billed every request |
| Cost with caching (static corpus) | Low — minimal change | Moderate — steep discount on Gemini/Claude cached tokens |
| Latency | ~1-2 s end-to-end | ~30-60 s for 100K-1M token prompts |
| Accuracy: single-fact lookup | Good — may miss if retriever fails | Very good — full context available |
| Accuracy: cross-document synthesis | Variable — depends on chunking | Better — model sees everything |
| Max corpus size | Unlimited — corpus lives in vector DB | Hard cap at context window (~1M tokens) |
| Data freshness | Real-time — update index, not prompt | Needs reload or re-cache on every change |
| Infrastructure complexity | Higher — embeddings, vector DB, retrieval tuning | Lower — just a big prompt |
Decision guide: when to use each approach
Three questions steer most decisions quickly.
- How big is your corpus? If it exceeds 1M tokens, long context is not an option — use RAG. If it fits in 50K-200K tokens, long context becomes technically viable.
- How often does your data change? If data updates hourly or daily, reloading or re-caching a large context is operationally painful; an indexed vector store handles incremental updates cleanly. If data is static — a single legal brief, a product spec that changes monthly — long context or a cached prompt is simpler.
- What does each query actually need to see? If a typical query needs 2% of your corpus, RAG delivers that 2% cleanly and the model is never distracted by the other 98%. If a typical query needs 80% of your corpus, RAG has to retrieve hundreds of chunks and you might as well load the whole thing.
Beyond those three, latency and cost requirements usually close the remaining cases. Sub-second response requirements rule out long context for large corpora. Cost-per-query budget at scale almost always favors RAG unless you have an aggressive caching strategy.
A useful mental shortcut: use long context for documents, use RAG for corpora. A single 300-page legal filing is a document — load it in full so the model can reason across every clause. A company's entire legal archive going back 20 years is a corpus — index it and retrieve the relevant filings per query.
The hybrid approach: routing between both
The most sophisticated production systems in 2025 do not pick a side — they route. Incoming queries are classified by what they need: a narrow factual lookup goes to RAG; a holistic "summarize the whole document" task goes to long context. This lets each approach work where it is strongest.
Research published at EMNLP 2024 on a technique called Self-Route demonstrated that letting the model reflect on whether it needs full context or focused retrieval — before answering — improved overall accuracy while cutting total compute cost significantly. The model's own uncertainty signal is a surprisingly reliable router.
A common pattern in agentic systems is to use RAG for the first pass — retrieving candidate documents — then feed those retrieved documents into a long-context prompt for the final synthesis step. This is sometimes called RAG + re-read: you narrow the search space with retrieval, then let the model reason freely over the shortlisted documents. It captures the cost benefits of RAG with the cross-document reasoning benefits of long context.
Going deeper
As both approaches mature, several advanced considerations become relevant for teams operating at scale.
Context caching as a cost bridge
Context caching is closing the cost gap for teams with read-heavy, static corpora. Gemini's explicit caching API lets you store a large prompt prefix — a full legal corpus, a product manual, a codebase — and reuse it across requests, paying only 10% of normal input token cost on each read. Claude's prompt caching works similarly, with a 90% discount on cached tokens, though the 5-minute idle eviction means it suits sustained traffic better than sporadic requests. For the right workloads — a single large document queried repeatedly within a session — caching makes long context competitive on cost.
The retrieval precision ceiling
RAG systems have a hard ceiling imposed by retrieval precision. Even with modern embedding models and rerankers, average recall on real multi-fact queries hovers around 60-70%. That means roughly one in three relevant facts never makes it into the prompt. Hybrid search (combining dense vector search with sparse BM25 keyword matching) and cross-encoder reranking push that number up, but never to the near-perfect recall that loading the full document provides. For use cases where missing a fact is catastrophic — medical, legal, compliance — the 40% miss rate is a serious liability that long context (or at minimum, hybrid RAG + long context) is designed to address.
Corpus scale as the deciding constraint
The 1M-token context window is genuinely large — roughly 750,000 words, or about 10 full-length novels. But enterprise knowledge bases routinely contain tens of millions of documents. A legal firm's document repository, a financial institution's filings archive, or a healthcare system's patient records are measured in petabytes, not megabytes. No context window today or in the near future scales to that. RAG is not competing with a 1M-token window on today's documents; it is the only architecture that works when your corpus is orders of magnitude larger than any window.
Where long context genuinely wins
There are concrete use cases where long context is simply the better tool. Code repository analysis — a model that reads an entire codebase to answer "what would break if I change this function?" needs full-graph visibility that RAG rarely captures. Contract comparison — finding subtle differences between two 200-page contracts requires both documents fully in context. Research summarization — synthesizing a 100-paper literature review is harder with retrieved chunks than with all papers in view. For these tasks, invest in the infrastructure for long context: generous token budgets, caching where possible, and tolerance for slower but higher-quality responses.
The verdict for 2025-2026: context windows did not kill RAG. They opened a new architectural option that complements retrieval rather than replacing it. The best systems are hybrid ones that route tasks to whichever approach fits the query's actual requirements — and measure both cost and accuracy to know when the routing decision is working.
FAQ
Do 1-million-token context windows make RAG obsolete?
No. Long context windows are a genuine alternative for small, static corpora, but they do not scale to the corpus sizes most enterprise applications need. A 1M-token window holds roughly 750,000 words — impressive, but a fraction of most knowledge bases. Beyond scale, cost and latency still strongly favor RAG for high-volume applications even when the corpus technically fits.
How much more expensive is long context than RAG at scale?
At production volumes, long context can cost 125x or more per query compared to a RAG pipeline on the same underlying model, because every token in the full corpus is billed on every request. Context caching (steep discounts on cached tokens from both Gemini and Claude) narrows the gap for read-heavy, static workloads, but cache eviction windows limit how much help this provides for sporadic traffic.
Is long context more accurate than RAG?
It depends on the task. Long context outperforms RAG on holistic tasks that require reasoning across an entire document — one study found it 34% more accurate on single-fact lookups from a complete document. But RAG was 67% more accurate on queries requiring synthesis across documents from different time periods, because retrieved chunks were precisely targeted and the model wasn't distracted by irrelevant content.
What is the 'lost in the middle' problem and has it been solved?
The "Lost in the Middle" effect refers to models struggling to use information buried in the middle of a very long context, with early studies showing accuracy drops of 30-50%. By 2025-2026, leading models have improved substantially: current frontier models from Google and OpenAI report near-perfect recall on needle-in-a-haystack evaluations. However, complex multi-fact queries across very long contexts still show measurable degradation compared to focused retrieval.
When should I use a hybrid approach combining RAG and long context?
Use a hybrid when different query types need different behavior. A common pattern is to use RAG to retrieve the most relevant documents, then load those retrieved documents into a long-context prompt for holistic synthesis. This captures RAG's cost and speed advantages for narrowing the search space, and long context's cross-document reasoning for the final answer. The Self-Route technique (EMNLP 2024) showed that letting the model decide which path it needs further improves accuracy.
Does context caching make long context cost-competitive with RAG?
For the right workloads, yes. If the same large corpus is queried many times within a short window, Gemini's steep cache discount or Claude's equivalent can bring the effective per-query cost much closer to RAG. The catch is that caching requires relatively static content and sustained traffic to amortize cache setup costs — it does not help for sporadic access or frequently updated corpora.