In plain English
RAG has a reputation problem — but not the kind you might expect. The problem is that it has become the default answer to every "how do I give an LLM context?" question, even when the question doesn't warrant it. Reach for RAG reflexively and you are committing to a vector database, an embedding model, a chunking strategy, a similarity-search layer, and all the evaluation headaches that come with tuning each one. That is a large bet to place before you have confirmed the problem requires it.
Think of RAG as a power tool: a rotary hammer is the right call for drilling through concrete, but you would not grab one to hang a picture frame. For smaller jobs the extra machinery slows you down, breaks things, and costs more than a simple nail. The same logic applies here. RAG is excellent for large, dynamic, private document corpora — but a surprising number of real AI products do not fit that description.
This article walks through the most common situations where RAG is the wrong tool, explains why simpler alternatives outperform it, and gives you a quick decision framework to avoid over-engineering your next project.
Why this matters for builders
Over-engineering costs real money and time. A dedicated vector database adds operational overhead: you must choose and provision a service (Pinecone, Weaviate, Qdrant, pgvector, etc.), maintain an embedding pipeline, keep the index in sync with your source data, and debug retrieval quality when answers degrade. For many teams that bill adds up before the first user query.
There is also a latency budget to consider. Each RAG request adds at least one embedding call plus a similarity-search round trip before the LLM even starts generating. For interactive chat and low-latency APIs, that extra 50–300 ms matters. If you could have served the answer from a static system prompt, you paid the penalty for nothing.
Finally, RAG introduces a retrieval failure mode that does not exist in simpler pipelines. If the retriever returns the wrong chunks — or no chunks — the model hallucinates or produces a worse answer than it would have with no retrieval at all. Adding RAG to a small or well-defined knowledge base can actually reduce answer quality compared to just putting the knowledge directly in the prompt.
When RAG earns its complexity — and when it doesn't
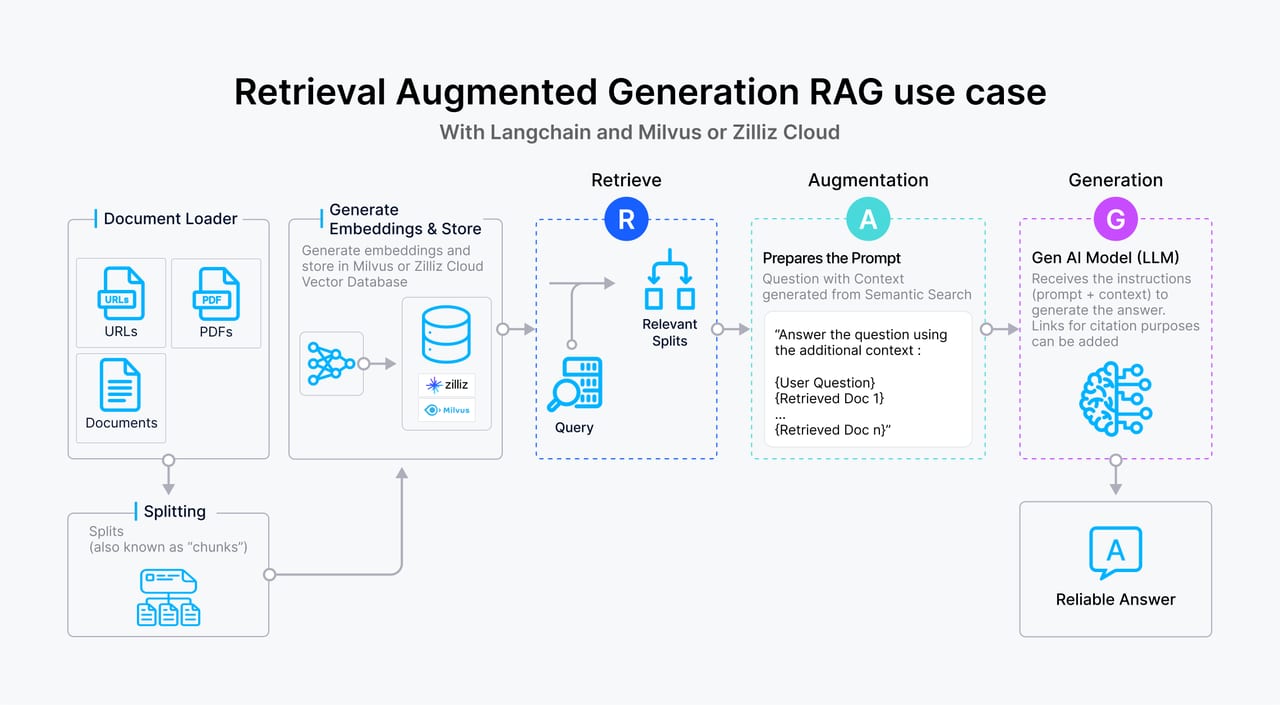
Before diagnosing the traps, it helps to understand what conditions make RAG genuinely useful. RAG pays off when three things are simultaneously true: the corpus is large (too big to fit in the context window), the corpus is dynamic (it changes frequently enough that baking it into weights is impractical), and the corpus is private (the base model was never trained on it). When all three conditions hold, retrieval is the right architecture.
- Large corpus (thousands of docs)
- Content changes frequently
- Private / never in training data
- Semantic search is the right retrieval mode
- Multiple query intents at runtime
- Small corpus (dozens of docs or fewer)
- Content is static or changes rarely
- Well-structured / tabular data
- Exact keyword match is sufficient
- Query space is narrow and predictable
The traps arise when builders reach for RAG even though one or more of those conditions is absent. The sections below describe the most common failure modes.
The five overengineering traps
Trap 1: Your corpus fits in the context window
Modern LLMs have large context windows — frontier models like Claude's Opus and Sonnet, the GPT-5 series, and Gemini 3 all accept very long inputs, with some tiers reaching into the millions of tokens. If your entire knowledge base is 20 product pages, 50 FAQ entries, or a single policy document, it almost certainly fits. In that case the right move is to paste the whole thing into the system prompt and skip retrieval entirely. You get deterministic, full-coverage answers with no retrieval failures, lower latency, and nothing new to maintain.
Trap 2: Your FAQ is static
A classic internal chatbot scenario: "We have 80 support FAQ answers. Let's build a RAG chatbot." Eighty answers almost certainly fit in a single prompt. Even if they don't, a traditional keyword search (BM25) over a static list outperforms vector similarity for exact phrase matches — and it needs no embedding model, no index, and no GPU. BM25 excels at matching specific product names, error codes, SKUs, and CLI flags that embedding models may blur into semantically adjacent but wrong results. The rule: if users are looking for specific known terms, not conceptual questions, keyword search is more accurate and dramatically simpler.
Trap 3: Your data is structured
RAG was designed for unstructured text — documents, articles, transcripts. When your data lives in a relational database, a spreadsheet, or an API with well-defined fields, vector similarity is the wrong retrieval primitive. A query like "show me Q3 revenue by region" needs an exact filter on structured fields, not a nearest-neighbour lookup in embedding space. The right approach is text-to-SQL (let the LLM write a SQL query from natural language) or a structured data layer that maps natural language to deterministic queries. Several production frameworks — LlamaIndex's NL-to-SQL, LangChain's SQLDatabaseChain, and purpose-built tools like DataBrain — handle this well without a single vector store.
# Instead of chunking your CSV and embedding it,
# let the LLM write the SQL query directly.
from langchain_community.utilities import SQLDatabase
from langchain_community.agent_toolkits import create_sql_agent
db = SQLDatabase.from_uri("sqlite:///sales.db")
agent = create_sql_agent(llm=llm, db=db, verbose=True)
agent.invoke("What was the total revenue in Q3 2025 by region?")
# The agent writes and executes SQL; no vectors involved.Trap 4: You need behavior changes, not knowledge injection
RAG changes what the model knows at runtime. It does nothing for how the model formats its responses, what tone it uses, or how it handles edge cases specific to your domain. If your problem is "the model doesn't follow our writing style" or "it keeps outputting the wrong JSON schema" or "it doesn't know that 'widget' means our core product" — none of those are retrieval problems. They are behavior problems. The right tools are prompt engineering for lightweight fixes, or fine-tuning for deep, repeatable behavioral changes. Adding RAG to a behavior problem adds retrieval failure modes without addressing the root cause.
Trap 5: Your query space is narrow and predictable
RAG shines when users can ask anything and the retriever must figure out which of thousands of documents is relevant. If your app accepts a small fixed set of query patterns — "summarize this uploaded PDF", "classify this support ticket into one of 12 categories", "extract the date and amount from this invoice" — you do not need general retrieval. You can pass the specific document (or a relevant section) directly in the prompt, or use a deterministic classifier before the LLM call. Agentic routing or simple intent classification is often a better fit than building a full retrieval stack.
A decision framework: pick the simplest tool that works
Rather than defaulting to RAG, work through this decision tree. Start simple and only add complexity when you have evidence that the simpler approach is insufficient.
| Situation | Problem | Better approach |
|---|---|---|
| 20-page product docs | Corpus fits in context | System prompt stuffing |
| 80 FAQ entries | Static, exact-match queries | BM25 keyword search |
| Sales database | Structured tabular data | Text-to-SQL (LangChain, LlamaIndex) |
| Wrong output format | Behavior, not knowledge | Prompt engineering or fine-tuning |
| Invoice extraction | Narrow, predictable query | Direct prompt with the document |
| 10,000-doc knowledge base, updates daily | Large, dynamic, private | RAG (this is where it belongs) |
Going deeper
Once you have confirmed that RAG is genuinely the right architecture for your problem, the next layer of decisions is retrieval quality. Two refinements matter most at production scale.
Hybrid retrieval: BM25 + vectors together
For real-world corpora that mix conceptual questions with exact-term lookups, neither BM25 alone nor vector search alone is optimal. Hybrid retrieval runs both in parallel and combines scores with a technique called Reciprocal Rank Fusion (RRF). Most mature retrieval stacks — including Elasticsearch 8.x with its knn clause, Redis Stack's FT.SEARCH with vector fields, and Qdrant's hybrid query API — support this natively. Starting with pure BM25 and adding vector similarity only when you have evidence that semantic matching improves results is a sound incremental strategy.
Long-context windows as a RAG alternative
The rise of 128k-to-1M token context windows has reopened the "just stuff it in" option for corpora that would have needed retrieval in 2023. Research from Databricks shows that for document-level question answering, long-context input can match or beat retrieval precision — but at a cost: token usage (and therefore API spend) scales linearly with corpus size, and model attention quality can degrade as context grows very long. For a stable corpus queried thousands of times per day, RAG still wins on cost. For a rapidly-changing corpus queried infrequently, long context may be simpler and good enough.
When RAG and fine-tuning are both wrong
A third scenario occasionally catches builders off-guard: the model does not need more knowledge or a behavior tweak — it needs to call a tool. If the right answer to a user question is always "look it up live from an API", neither RAG (which indexes static snapshots) nor fine-tuning (which bakes in past patterns) is the right primitive. Function calling / tool use lets the model decide at runtime to query a live endpoint, run a calculation, or look up a current price — without any indexing pipeline at all. Before building a vector store for real-time data, check whether a tool call is the cleaner solution.
FAQ
At what corpus size should I start considering RAG?
There is no exact threshold, but a practical starting point is: if your knowledge base exceeds roughly 100 dense pages (around 150,000–200,000 tokens), it may no longer fit reliably in a context window, and retrieval starts to make economic sense. Below that, experiment with prompt-stuffing first and only add a vector store if you observe retrieval quality or cost problems you cannot solve otherwise.
Can I use RAG for structured database data?
RAG is a poor fit for structured data — it is designed for unstructured text. When your data lives in tables, a text-to-SQL approach (where the LLM generates a SQL query from natural language) is almost always more accurate and less complex. Libraries like LangChain's SQLDatabaseChain and LlamaIndex's NL-to-SQL module handle this pattern well.
Is a vector database always required for RAG?
No. For small corpora (under a few thousand documents), in-memory libraries like FAISS or simple numpy dot-product search are often sufficient and add no infrastructure overhead. A dedicated vector database (Pinecone, Qdrant, Weaviate, pgvector) only becomes necessary when you need persistence, multi-tenant isolation, or indexing at a scale that exceeds memory.
When should I fine-tune instead of using RAG?
Fine-tune when you need to change how the model behaves — its tone, output format, domain vocabulary, or refusal patterns — rather than what it knows. RAG injects knowledge at query time but cannot reliably reshape model behavior. Fine-tuning is also worth exploring when you have high-volume, narrow-domain queries where a smaller, tuned model can outperform a larger general model with RAG at a fraction of the inference cost.
Does a large context window make RAG obsolete?
Not yet, and probably not for high-volume production apps. Stuffing a 500-page corpus into every request is viable for infrequent queries, but the token cost scales linearly — RAG can reduce per-query token usage by 50x or more by retrieving only the relevant 2,000–10,000 tokens. Long context wins on simplicity for small or rarely-queried corpora; RAG wins on cost efficiency at scale.
What is the cheapest way to add a knowledge base to an LLM app?
For most early-stage projects, the cheapest approach is to paste the entire knowledge base into the system prompt. If the corpus is too large for that, BM25 keyword search (via a library like rank_bm25 in Python) over your documents costs nothing to run and zero infrastructure to maintain. Only add embedding models and a vector store once you have confirmed that semantic (conceptual) matching is actually necessary for your query patterns.